# Js是怎样运行起来的?
# 前言
不知道大家有没有想过这样一个问题,我们所写的 JavaScript 代码是怎样被计算机认识并且执行的呢?这中间的过程具体是怎样的呢? 有的同学可能已经知道,Js 是通过 Js 引擎运行起来的,那么
有的同学可能已经知道,Js 是通过 Js 引擎运行起来的,那么
什么是 Js 引擎?
Js 引擎是怎样编译执行和优化 Js 代码的?
Js 引擎有很多种,比如 Chrome 使用的 V8 引擎,Webkit 使用的是 JavaScriptCore,React Native 使用的是 Hermes。今天我们主要来分析一下比较主流的 V8 引擎是怎样运行 Js 的。
# V8 引擎
在介绍 V8 引擎的概念之前,我们先来回顾一下编程语言。编程语言可以分为机器语言、汇编语言、高级语言。
机器语言:由 0 和 1 组成的二进制码,对于人类来说是很难记忆的,还要考虑不同 CPU 平台的兼容性。
汇编语言:用更容易记忆的英文缩写标识符代替二进制指令,但还是需要开发人员有足够的硬件知识。
高级语言:更简单抽象且不需要考虑硬件,但是需要更复杂、耗时更久的翻译过程才能被执行。
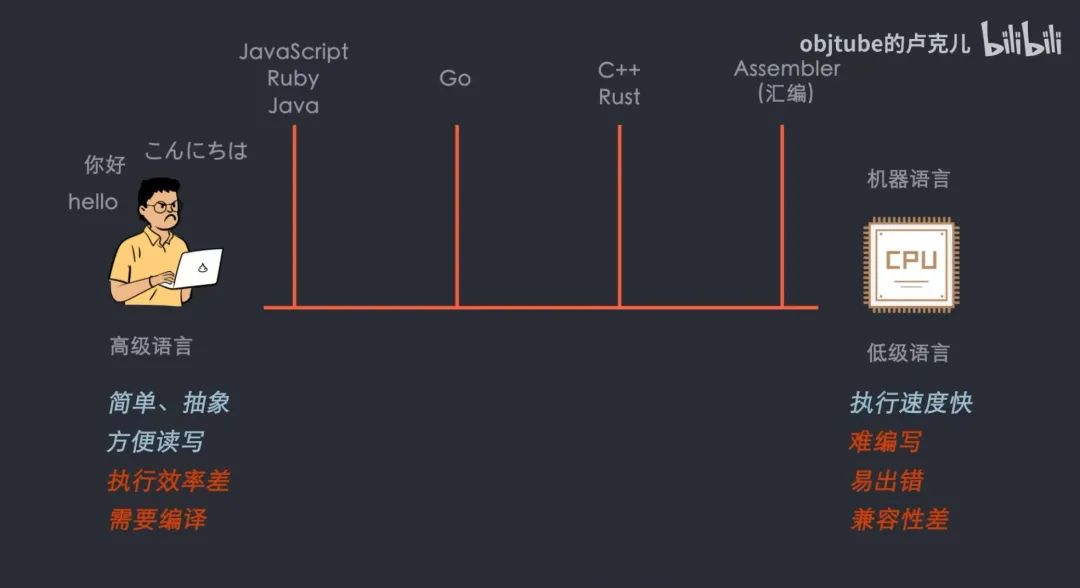 到了这里我们知道,高级语言一定要转化为机器语言才能被计算机执行,而且越高级的语言转化的时间越久。高级语言又可以分为解释型语言、编译型语言。
到了这里我们知道,高级语言一定要转化为机器语言才能被计算机执行,而且越高级的语言转化的时间越久。高级语言又可以分为解释型语言、编译型语言。
编译型语言:需要编译器进行一次编译,被编译过的文件可以多次执行。如 C++、C 语言。
解释型语言:不需要事先编译,通过解释器一边解释一边执行。启动快,但执行慢。
我们知道 JavaScript 是一门高级语言,并且是动态类型语言,我们在定义一个变量时不需要关心它的类型,并且可以随意的修改变量的类型。而在像 C++这样的静态类型语言中,我们必须提前声明变量的类型并且赋予正确的值才行。也正是因为 JavaScript 没有像 C++那样可以事先提供足够的信息供编译器编译出更加低级的机器代码,它只能在运行阶段收集类型信息,然后根据这些信息进行编译再执行,所以 JavaScript 也是解释型语言。
这也就意味着 JavaScript 要想被计算机执行,需要一个能够快速解析并且执行 JavaScript 脚本的程序,这个程序就是我们平时所说的 JavaScript 引擎。这里我们给出 V8 引擎的概念:V8 是 Google 基于 C++ 编写的开源高性能 Javascript 与 WebAssembly 引擎。用于 Google Chrome(Google 的开源浏览器) 以及 Node.js 等。
# CPU 是如何执行机器指令的?
将高级语言转化为机器语言之后,CPU 又是怎样执行的呢?我们以一段 C 代码为例:
int main()
{
int x = 1;
int y = 2;
int z = x + y;
return z;
}}
先来看一下以上代码被转换为机器语言是什么样子。下图左侧是用十六进制表示的二进制机器码,中间部分是汇编代码,右侧是指令的含义。
# CPU 执行机器指令的流程
首先程序在执行之前会被装进内存。
系统会将二进制代码中的第一条指令的地址写入到 PC 寄存器中。
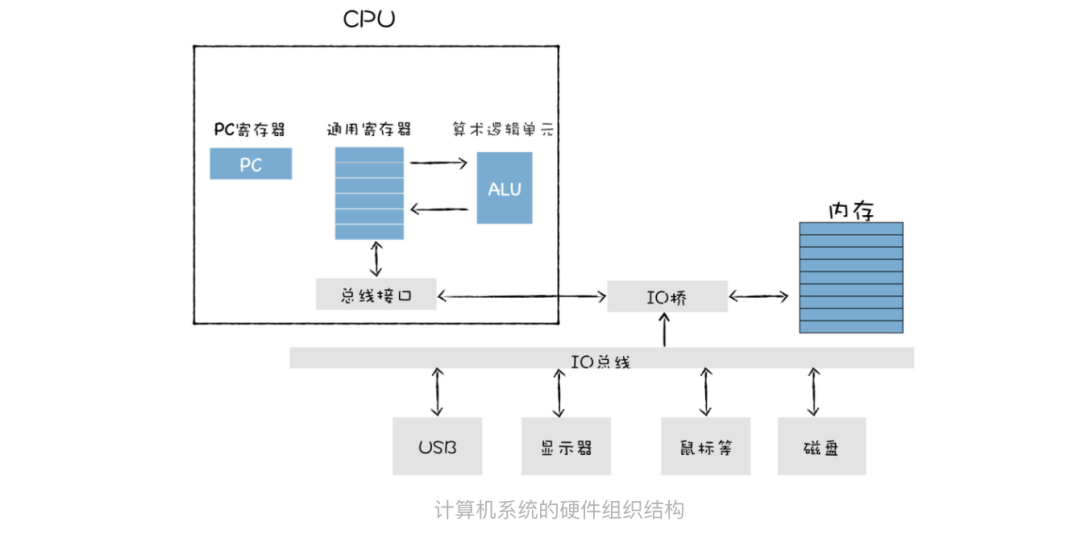
CPU 根据 PC 寄存器中的地址,从内存中取出指令。
将下一条指令的地址更新到 PC 寄存器中。
分析当前取出指令,并识别出不同的类型的指令,以及各种获取操作数的方法。
加载指令:从内存中复制指定长度的内容到通用寄存器中,并覆盖寄存器中原来的内容。
存储指令:将寄存器中的内容复制到内存某个位置,并覆盖掉内存中的这个位置上原来的内容。
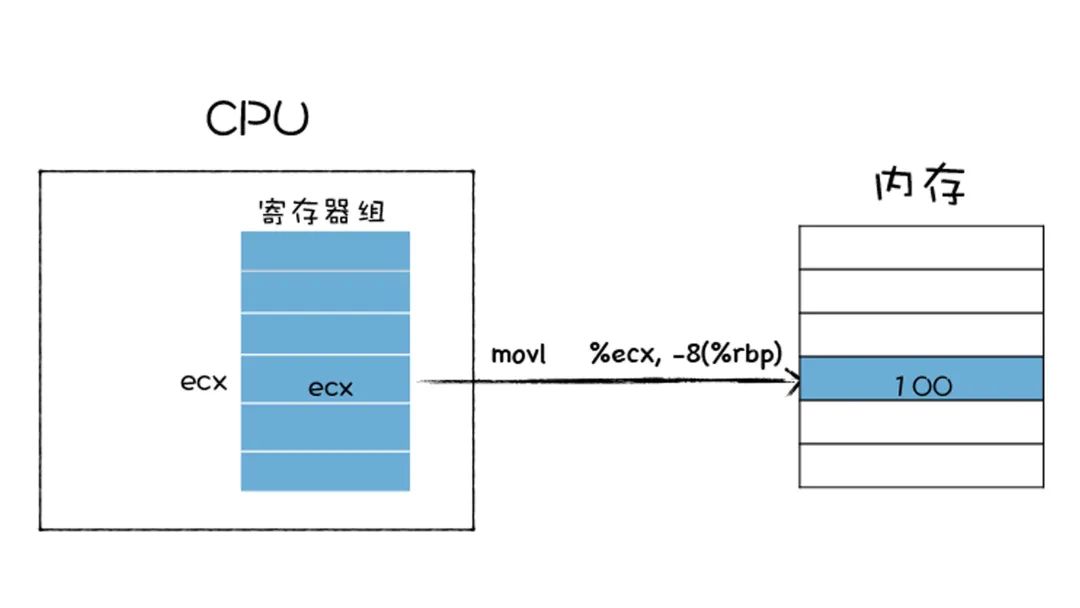 上图中 movl 指令后面的 %ecx 就是寄存器地址,-8(%rbp) 是内存中的地址,这条指令的作用是将寄存器中的值拷贝到内存中。
上图中 movl 指令后面的 %ecx 就是寄存器地址,-8(%rbp) 是内存中的地址,这条指令的作用是将寄存器中的值拷贝到内存中。
- 更新指令:复制两个寄存器中的内容到 ALU 中,也可以是一块寄存器和一块内存中的内容到 ALU 中,ALU 将两个字相加,并将结果存放在其中的一个寄存器中,并覆盖该寄存器中的内容。
...
- 执行指令完毕,进入下一个 CPU 时钟周期。
# V8 引擎的编译流水线
接下来我们先从宏观的角度来看一下 V8 是怎么执行 JavaScript 代码的,然后再对每一步进行分析。
初始化基础环境;
解析源码生成 AST 和作用域;
依据 AST 和作用域生成字节码;
解释执行字节码;监听热点代码;
...
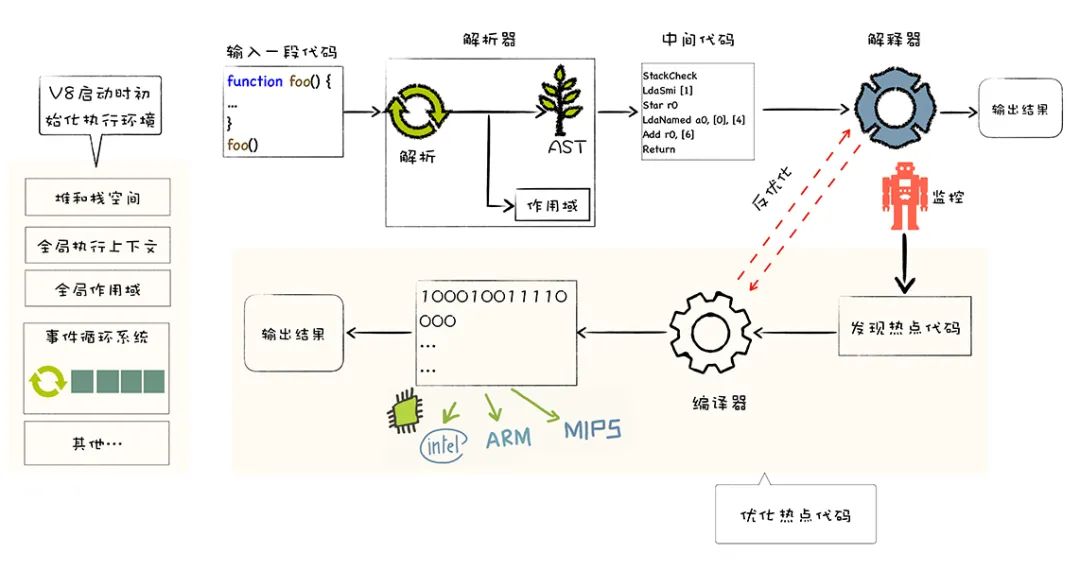
# 完整的分析一段 JavaScript 代码是怎样被执行的
# 1、初始化基础环境
V8 执行 Js 代码是离不开宿主环境的,V8 的宿主可以是浏览器,也可以是 Node.js。下图是浏览器的组成结构,其中渲染引擎就是平时所说的浏览器内核,它包括网络模块,Js 解释器等。当打开一个渲染进程时,就为 V8 初始化了一个运行时环境。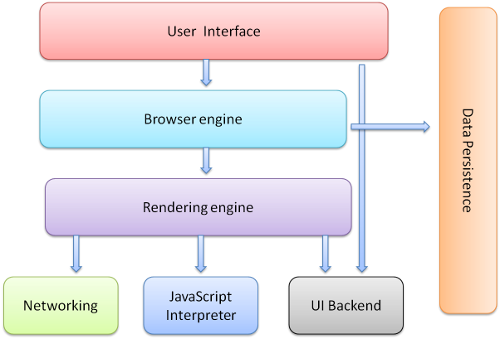 运行时环境为 V8 提供了堆空间,栈空间、全局执行上下文、消息循环系统、宿主对象及宿主 API 等。V8 的核心是实现了 ECMAScript 标准,此外还提供了垃圾回收器等内容。
运行时环境为 V8 提供了堆空间,栈空间、全局执行上下文、消息循环系统、宿主对象及宿主 API 等。V8 的核心是实现了 ECMAScript 标准,此外还提供了垃圾回收器等内容。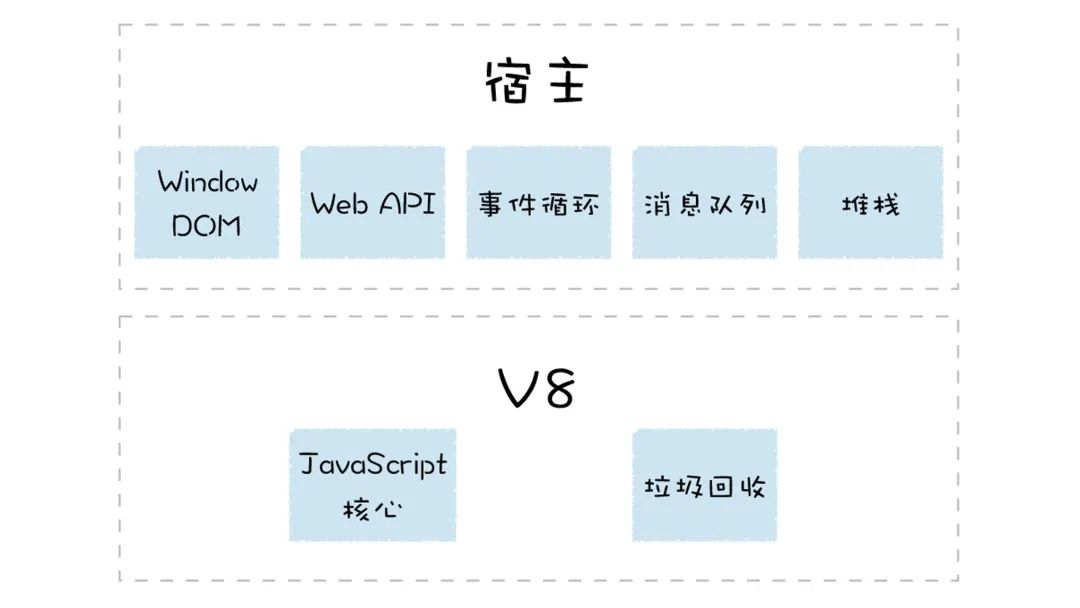
# 2、解析源码生成 AST 和作用域
基础环境准备好之后,接下来就可以向 V8 提交要执行的 JavaScript 代码了。首先 V8 会接收到要执行的 JavaScript 源代码,不过这对 V8 来说只是一堆字符串,V8 并不能直接理解这段字符串的含义,它需要结构化这段字符串。
function add(x, y) {
var z = x+y
return z
}
console.log(add(1, 2))
比如针对如上源代码,V8 首先通过解析器(parser)解析成如下的抽象语法树 AST:
[generating bytecode for function: add]
--- AST ---
FUNC at 12
KIND 0
LITERAL ID 1
SUSPEND COUNT 0
NAME "add"
PARAMS
VAR (0x7fa7bf8048e8) (mode = VAR, assigned = false) "x"
VAR (0x7fa7bf804990) (mode = VAR, assigned = false) "y"
DECLS
VARIABLE (0x7fa7bf8048e8) (mode = VAR, assigned = false) "x"
VARIABLE (0x7fa7bf804990) (mode = VAR, assigned = false) "y"
VARIABLE (0x7fa7bf804a38) (mode = VAR, assigned = false) "z"
BLOCK NOCOMPLETIONS at -1
EXPRESSION STATEMENT at 31
INIT at 31
VAR PROXY local[0] (0x7fa7bf804a38) (mode = VAR, assigned = false) "z"
ADD at 32
VAR PROXY parameter[0] (0x7fa7bf8048e8) (mode = VAR, assigned = false) "x"
VAR PROXY parameter[1] (0x7fa7bf804990) (mode = VAR, assigned = false) "y"
RETURN at 37
VAR PROXY local[0] (0x7fa7bf804a38) (mode = VAR, assigned = false) "z"
V8 在生成 AST 的同时,还生成了 add 函数的作用域:
Global scope:
function add (x, y) { // (0x7f9ed7849468) (12, 47)
// will be compiled
// 1 stack slots
// local vars:
VAR y; // (0x7f9ed7849790) parameter[1], never assigned
VAR z; // (0x7f9ed7849838) local[0], never assigned
VAR x; // (0x7f9ed78496e8) parameter[0], never assigned
}
在解析期间,所有函数体中声明的变量和函数参数,都被放进作用域中,如果是普通变量,那么默认值是 undefined,如果是函数声明,那么将指向实际的函数对象。在执行阶段,作用域中的变量会指向堆和栈中相应的数据。
# 3、依据 AST 和作用域生成字节码
生成了作用域和 AST 之后,V8 就可以依据它们来生成字节码了。AST 之后会被作为输入传到字节码生成器 (BytecodeGenerator),这是 Ignition 解释器中的一部分,用于生成以函数为单位的字节码。
[generated bytecode for function: add (0x079e0824fdc1 <SharedFunctionInfo add>)]
Parameter count 3
Register count 2
Frame size 16
0x79e0824ff7a @ 0 : a7 StackCheck
0x79e0824ff7b @ 1 : 25 02 Ldar a1
0x79e0824ff7d @ 3 : 34 03 00 Add a0, [0]
0x79e0824ff80 @ 6 : 26 fb Star r0
0x79e0824ff82 @ 8 : 0c 02 LdaSmi [2]
0x79e0824ff84 @ 10 : 26 fa Star r1
0x79e0824ff86 @ 12 : 25 fb Ldar r0
0x79e0824ff88 @ 14 : ab Return
Constant pool (size = 0)
Handler Table (size = 0)
Source Position Table (size = 0)
# 4、解释执行字节码
和 CPU 执行二进制机器代码类似:使用内存中的一块区域来存放字节码;使通用寄存器用来存放一些中间数据;PC 寄存器用来指向下一条要执行的字节码;栈顶寄存器用来指向当前的栈顶的位置。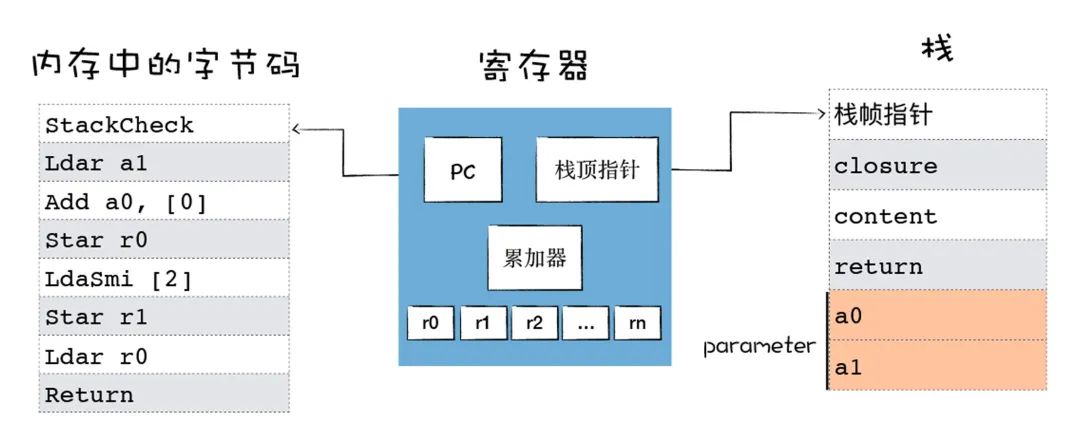
StackCheck 字节码指令就是检查栈是否达到了溢出的上限。
Ldar 表示将寄存器中的值加载到累加器中。
Add 表示寄存器加载值并将其与累加器中的值相加,然后将结果再次放入累加器。
Star 表示 把累加器中的值保存到某个寄存器中。
Return 结束当前函数的执行,并将控制权传回给调用方。返回的值是累加器中的值。
# 5、即时编译
在解释器 Ignition 执行字节码的过程中,如果发现有热点代码(HotSpot),比如一段代码被重复执行多次,这种就称为热点代码,那么后台的编译器 TurboFan 就会把该段热点的字节码编译为高效的机器码,然后当再次执行这段被优化的代码时,只需要执行编译后的机器码就可以了,这样就大大提升了代码的执行效率。这种字节码配合解释器和编译器的技术被称为即时编译(JIT)。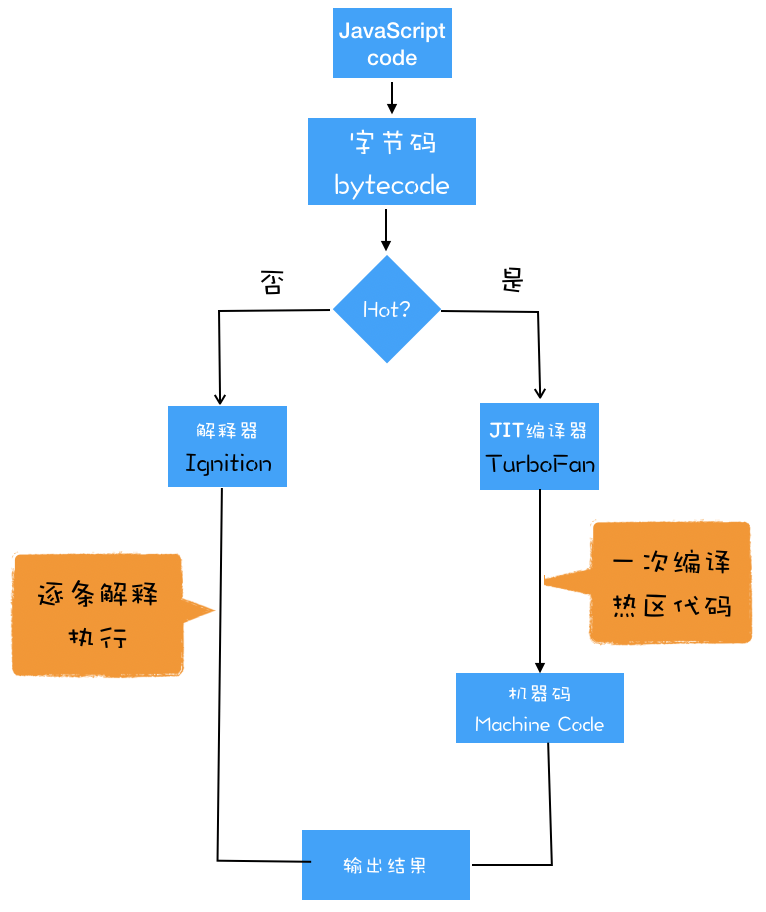
# V8 的优化策略
下面我们来看一下,V8 为了提升解析和执行 Js 的速度,做了哪些优化。由于篇幅关系,这里只介绍 5 个优化点。
# 1、重新引入字节码
早期的 V8 团队认为先生成字节码再执行字节码的方式会降低代码的执行效率,于是直接将 JavaScript 代码编译成机器代码。这样做带来的问题有两点,一是需要较长的编译时间,二是产生的二进制机器码需要占用较大的内存空间。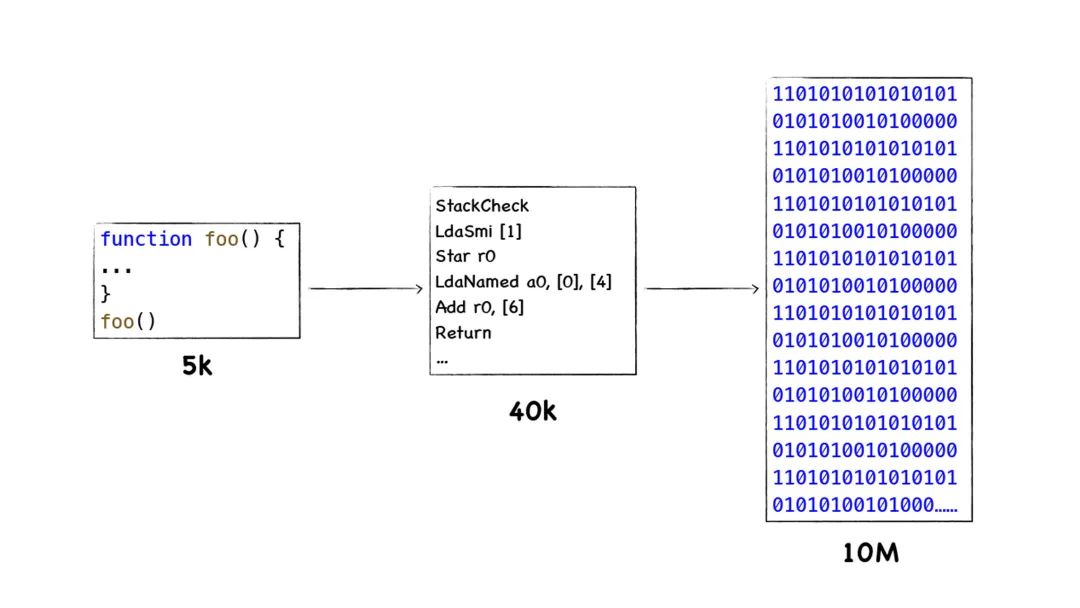 使用字节码的话虽然牺牲了一点执行效率,但是节省了内存空间并且降低了编译时间。此外,字节码也降低了 V8 代码的复杂度,使得 V8 移植到不同的 CPU 架构平台更加容易。这是因为统一将字节码转换为不同平台的二进制代码要比编译器编写不同 CPU 体系的二进制代码更加容易。
使用字节码的话虽然牺牲了一点执行效率,但是节省了内存空间并且降低了编译时间。此外,字节码也降低了 V8 代码的复杂度,使得 V8 移植到不同的 CPU 架构平台更加容易。这是因为统一将字节码转换为不同平台的二进制代码要比编译器编写不同 CPU 体系的二进制代码更加容易。
# 2、延迟解析
通过 V8 的编译流程我们可以看出,V8 执行 JavaScript 代码需要经过编译和执行两个阶段。
编译过程:是指 V8 将 JavaScript 代码转换为字节码,或者二进制机器代码的阶段。
执行阶段:是指解释器解释执行字节码,或者是 CPU 直接执行二进制机器代码的阶段。
V8 并不会一次性将所有的 JavaScript 解析为中间代码,这主要是基于以下两点:
如果一次解析和编译所有的 JavaScript 代码,过多的代码会增加编译时间,这会严重影响到首次执行 JavaScript 代码的速度,让用户感觉到卡顿。
其次,解析完成的字节码和编译之后的机器代码都会存放在内存中,如果一次性解析和编译所有 JavaScript 代码,那么这些中间代码和机器代码将会一直占用内存。
延迟解析是指解析器在解析的过程中,如果遇到函数声明,那么会跳过函数内部的代码,并不会为其生成 AST 和字节码。
# 3、隐藏类
我们可以结合一段代码来分析下隐藏类是怎么工作的:
let point = {x:100,y:200}
当 V8 执行到这段代码时,会先为 point 对象创建一个隐藏类,在 V8 中,把隐藏类又称为 map,每个对象都有一个 map 属性,其值指向内存中的隐藏类。隐藏类描述了对象的属性布局,它主要包括了属性名称和每个属性所对应的偏移量,比如 point 对象的隐藏类就包括了 x 和 y 属性,x 的偏移量是 4,y 的偏移量是 8。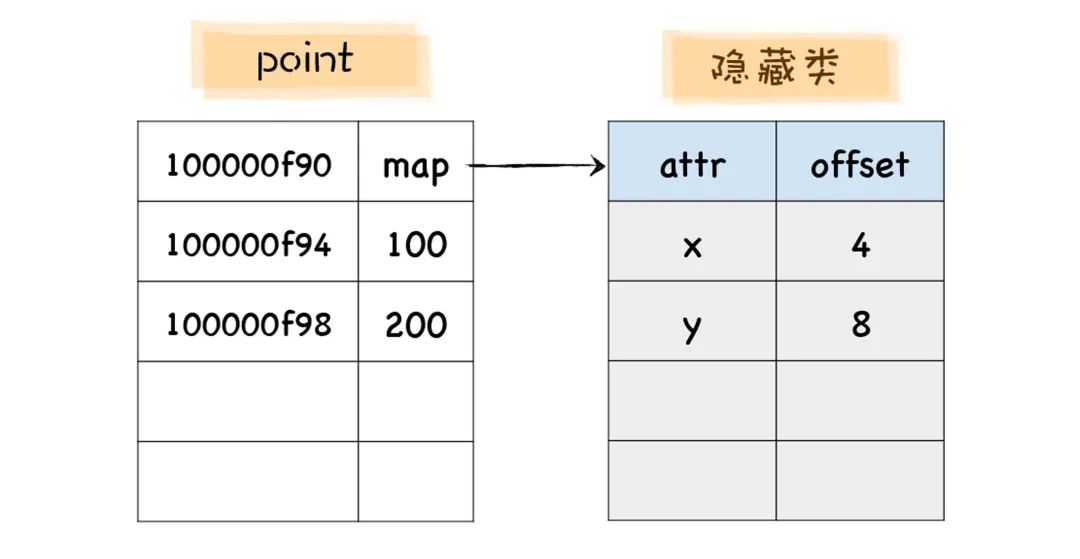 有了隐藏类之后,那么当 V8 访问某个对象中的某个属性时,就会先去隐藏类中查找该属性相对于它的对象的偏移量,有了偏移量和属性类型,V8 就可以直接去内存中取出对应的属性值,而不需要经历一系列的查找过程,那么这就大大提升了 V8 查找对象的效率。
有了隐藏类之后,那么当 V8 访问某个对象中的某个属性时,就会先去隐藏类中查找该属性相对于它的对象的偏移量,有了偏移量和属性类型,V8 就可以直接去内存中取出对应的属性值,而不需要经历一系列的查找过程,那么这就大大提升了 V8 查找对象的效率。
# 4、快属性与慢属性
当我们在控制台输入如下代码时:
function Foo() {
this[100] = 'test-100'
this[1] = 'test-1'
this["B"] = 'bar-B'
this[50] = 'test-50'
this[9] = 'test-9'
this[8] = 'test-8'
this[3] = 'test-3'
this[5] = 'test-5'
this["A"] = 'bar-A'
this["C"] = 'bar-C'
}
var bar = new Foo()
for(key in bar){
console.log(`index:${key} value:${bar[key]}`)
}
打印出来的结果如下:
index:1 value:test-1
index:3 value:test-3
index:5 value:test-5
index:8 value:test-8
index:9 value:test-9
index:50 value:test-50
index:100 value:test-100
index:B value:bar-B
index:A value:bar-A
index:C value:bar-C
之所以出现这样的结果,是因为在 ECMAScript 规范中定义了数字属性应该按照索引值大小升序排列,字符串属性根据创建时的顺序升序排列。
数字属性称为排序属性,在 V8 中被称为 elements。
字符串属性就被称为常规属性,在 V8 中被称为 properties。
下面我们执行这样一段代码,看一看当对象中的属性数目发生变化时,其在内存中结构是怎样变化的。
function Foo(property_num,element_num) {
//添加排序属性
for (let i = 0; i < element_num; i++) {
this[i] = `element${i}`
}
//添加常规属性
for (let i = 0; i < property_num; i++) {
let ppt = `property${i}`
this[ppt] = ppt
}
}
var bar = new Foo(10,10)
将 Chrome 开发者工具切换到 Memory 标签,然后点击左侧的小圆圈就可以捕获以上代码的内存快照,最终截图如下所示: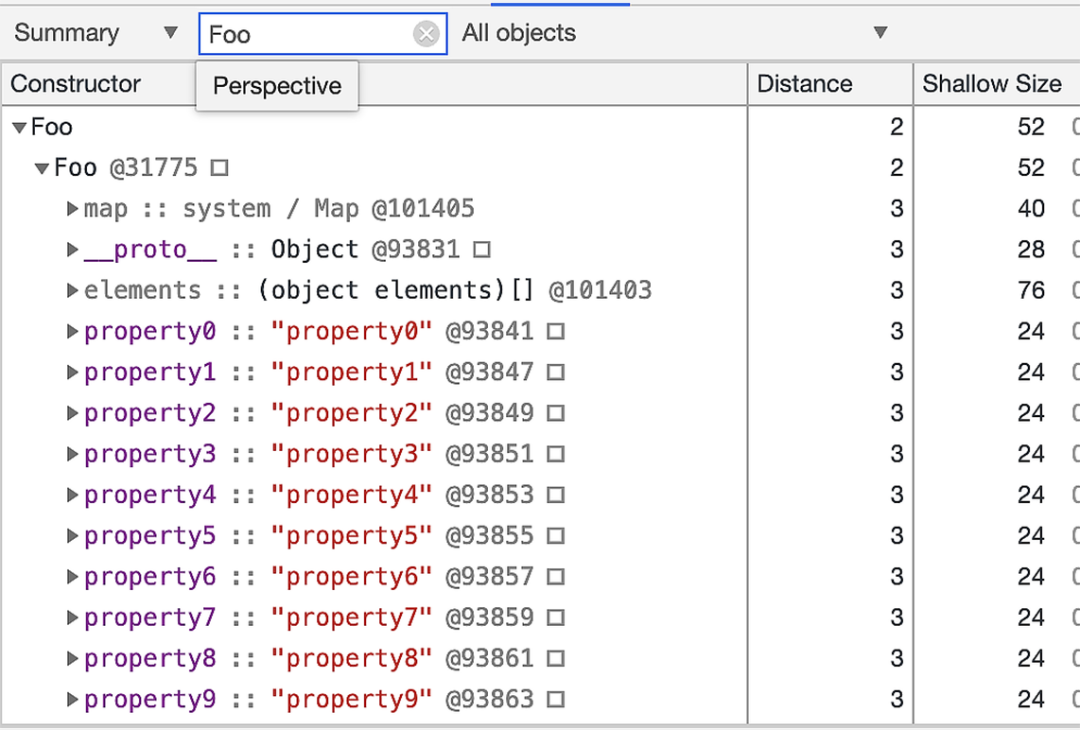 将创建的对象属性的个数调整到 20 个
将创建的对象属性的个数调整到 20 个
var bar2 = new Foo(20,10)
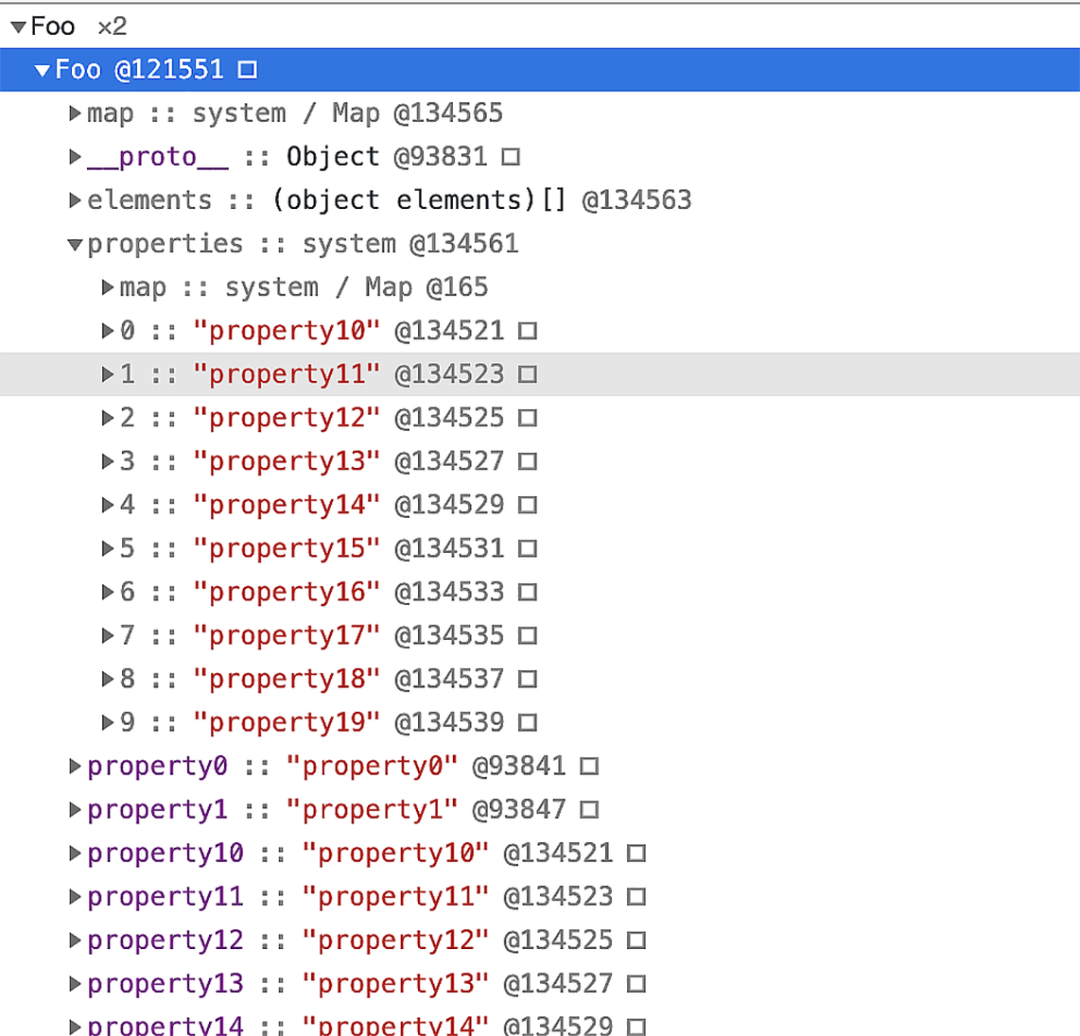 总结:当对象中的属性过多时,或者存在反复添加或者删除属性的操作,那么 V8 就会将线性的存储模式(快属性)降级为非线性的字典存储模式(慢属性),这样虽然降低了查找速度,但是却提升了修改对象的属性的速度。
总结:当对象中的属性过多时,或者存在反复添加或者删除属性的操作,那么 V8 就会将线性的存储模式(快属性)降级为非线性的字典存储模式(慢属性),这样虽然降低了查找速度,但是却提升了修改对象的属性的速度。
# 5、内联缓存
我们再来看一段这样的代码。
function loadX(o) {
o.y = 4
return o.x
}
var o = { x: 1,y:3}
var o1 = { x: 3 ,y:6}
for (var i = 0; i < 90000; i++) {
loadX(o)
loadX(o1)
}
通常 V8 获取 o.x 的流程是这样的:查找对象 o 的隐藏类,再通过隐藏类查找 x 属性偏移量,然后根据偏移量获取属性值,在这段代码中 loadX 函数会被反复执行,那么获取 o.x 流程也需要反复被执行。为了提升对象的查找效率。V8 执行的策略就是使用内联缓存 (Inline Cache),简称为 IC。IC 会为每个函数维护一个反馈向量 (FeedBack Vector),反馈向量记录了函数在执行过程中的一些关键的中间数据。然后将这些数据缓存起来,当下次再次执行该函数时,V8 就可以直接利用这些中间数据,节省了再次获取这些数据的过程。V8 会在反馈向量中为每个调用点分配一个插槽(Slot),比如 o.y = 4 和 return o.x 这两段就是调用点 (CallSite),因为它们使用了对象和属性。每个插槽中包括了插槽的索引 (slot index)、插槽的类型 (type)、插槽的状态 (state)、隐藏类 (map) 的地址、还有属性的偏移量,比如上面这个函数中的两个调用点都使用了对象 o,那么反馈向量两个插槽中的 map 属性也都是指向同一个隐藏类的,因此这两个插槽的 map 地址是一样的。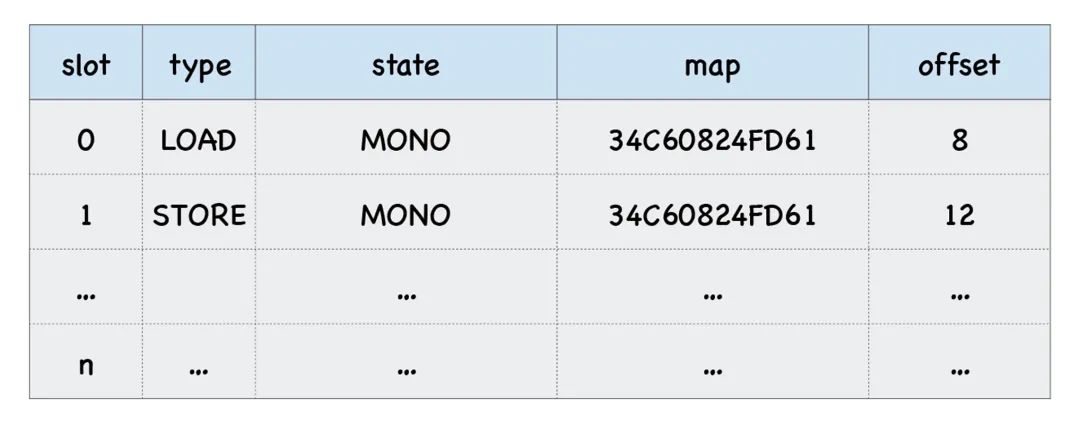 通过内联缓存策略,就能够提升下次执行函数时的效率,但是这有一个前提,那就是多次执行时,对象的形状是固定的,如果对象的形状不是固定的,这意味着 V8 为它们创建的隐藏类也是不同的。面对这种情况,V8 会选择将新的隐藏类也记录在反馈向量中,同时记录属性值的偏移量,这时,反馈向量中的一个槽里就会出现包含了多个隐藏类和偏移量的情况,如果超过 4 个,那么 V8 会采取 hash 表的结构来存储。讲到这里我的分享就结束了,如果有不足之处欢迎大家多多批评指正。
通过内联缓存策略,就能够提升下次执行函数时的效率,但是这有一个前提,那就是多次执行时,对象的形状是固定的,如果对象的形状不是固定的,这意味着 V8 为它们创建的隐藏类也是不同的。面对这种情况,V8 会选择将新的隐藏类也记录在反馈向量中,同时记录属性值的偏移量,这时,反馈向量中的一个槽里就会出现包含了多个隐藏类和偏移量的情况,如果超过 4 个,那么 V8 会采取 hash 表的结构来存储。讲到这里我的分享就结束了,如果有不足之处欢迎大家多多批评指正。
「招聘内推码:9S66W8E」

参考链接
https://www.cnblogs.com/nickchen121/p/10722720.html
https://v8.dev/docs
https://juejin.cn/post/6844904161163608078
https://time.geekbang.org/column/article/211682
https://www.jianshu.com/p/e4a75cb6f268
关于本文
来源:字节前端 ByteFE
https://mp.weixin.qq.com/s/3ROdZZ_xTtl6B5ii4ha46w
汇总 →